
Amazon Redshift Unleashes Graviton-Powered RG Instances for Next-Generation AI and Data Lake Analytics
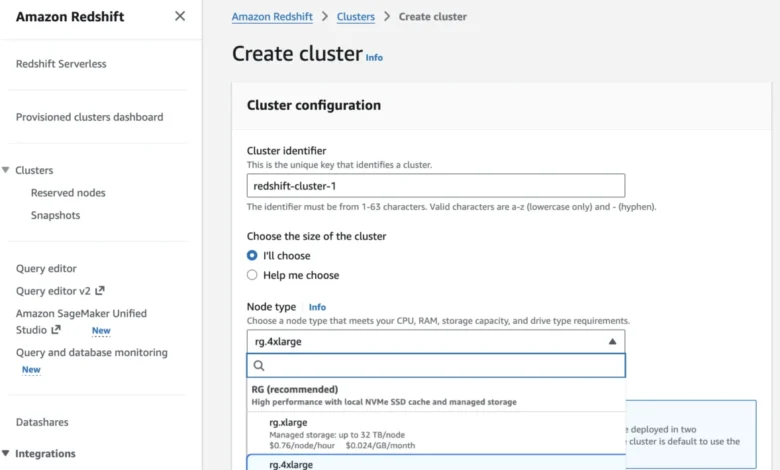
Amazon Web Services (AWS) has announced the immediate availability of Amazon Redshift RG instances, a new family of data warehouse compute instances powered by AWS Graviton processors, engineered to deliver unparalleled performance and cost efficiency for modern analytics and emerging artificial intelligence (AI) agent workloads. This significant update marks a new chapter in Redshift’s decade-long evolution, promising up to 2.2 times faster data warehouse query execution and up to 30% lower price per vCPU compared to previous-generation RA3 instances, alongside a seamlessly integrated data lake query engine that drastically improves performance for open formats like Apache Iceberg and Apache Parquet.
A Decade of Data Warehousing Innovation Culminating in the AI Era
Since its inception in 2013, Amazon Redshift has consistently aimed to democratize high-performance data warehousing, offering a cloud-native solution at a fraction of the cost of traditional on-premises alternatives. The journey has seen several architectural breakthroughs, each designed to make data queries cheaper, faster, and more efficient. Early iterations focused on dense compute, followed by the introduction of Amazon RA3 instances with managed analytics-optimized storage, which decoupled compute from storage for greater flexibility and scalability. More recently, Amazon Redshift Serverless brought an on-demand, pay-per-use model, further simplifying operations and cost management for fluctuating workloads. These foundational advancements set the stage for the current demands of data-intensive organizations.
Over the past decade, the landscape of data analytics has undergone a profound transformation. Data volumes have not only exploded but have also diversified, with organizations increasingly adopting hybrid architectures that leverage both highly structured data warehouse tables for frequently accessed, critical data, and vast data lakes for cost-effective storage of varied, unstructured, or semi-structured datasets. This dual approach, often termed a "lakehouse" architecture, presents unique challenges in terms of data integration, query performance, and cost management. Furthermore, the burgeoning field of artificial intelligence has introduced a new dimension to data consumption. AI agents, unlike human users, can query data warehouses at an unprecedented scale and frequency, generating query volumes that can dwarf typical human usage and lead to spiraling operational costs if not managed efficiently.
Recognizing these evolving needs, Amazon Redshift has continued to invest heavily in its core strengths. As recently as March 2026, the service demonstrated its commitment to performance by announcing improvements that accelerated new queries by up to seven times. This enhancement was specifically targeted at improving response times for low-latency SQL queries crucial for near-real-time analytics applications, business intelligence (BI) dashboards, ETL (Extract, Transform, Load) pipelines, and, notably, autonomous, goal-seeking AI agents. The introduction of RG instances is a direct and powerful response to these accelerating demands, particularly from the AI domain.
The Power of Graviton: Fueling Next-Generation Analytics
The cornerstone of the new Redshift RG instances is the AWS Graviton processor. Graviton, a custom-designed ARM-based processor by AWS, represents a strategic investment in delivering superior price-performance efficiency across a wide range of cloud workloads. First introduced in 2018, Graviton processors have progressively been integrated into various AWS services, including Amazon EC2, Amazon RDS, Amazon Aurora, and AWS Lambda, consistently demonstrating significant performance improvements and cost reductions compared to x86-based instances. By bringing Graviton to Amazon Redshift, AWS is extending these benefits to the demanding realm of cloud data warehousing.
RG instances leverage the inherent architectural advantages of Graviton, enabling them to run data warehouse workloads up to 2.2 times faster than their RA3 counterparts. This speed enhancement is critical for applications requiring rapid data insights, such as real-time operational analytics, fraud detection systems, and dynamic pricing models. Beyond raw speed, the efficiency of Graviton processors translates directly into cost savings, with RG instances offering a 30% lower price per vCPU. This combination of heightened performance and reduced cost is a compelling proposition for organizations seeking to optimize their analytics spend without compromising on capability.
Unified Analytics: Bridging the Data Warehouse and Data Lake Divide
One of the most significant innovations of Redshift RG instances is their integrated data lake query engine. Traditionally, querying data stored in Amazon Simple Storage Service (Amazon S3) data lakes from Redshift required the use of Amazon Redshift Spectrum, a separate service that incurred per-terabyte scanning charges. While effective, this approach added complexity and cost, and sometimes introduced latency dueips to the need to offload queries.
With RG instances, data lake queries are now executed directly on the cluster nodes – the same compute resources that process data warehouse workloads. This fundamental shift eliminates the need for Redshift Spectrum and, critically, removes the associated $5 per terabyte scanning fees that previously contributed to the total cost of ownership for customers leveraging data lakes. More than just cost savings, this integration offers several profound benefits:
- Performance Boost: The integrated engine delivers significantly improved performance for querying data in open formats. For Apache Iceberg, RG instances are up to 2.4 times faster than RA3 instances, and for Apache Parquet, they are up to 1.5 times faster. Apache Iceberg and Parquet are widely adopted open table formats and file formats, respectively, known for their efficiency and flexibility in large-scale data lake environments. The enhanced speed means faster insights from diverse datasets, whether they reside in the structured data warehouse or the flexible data lake.
- Operational Simplicity: Unifying the query engine simplifies the overall analytics architecture. Data engineers and analysts can now run SQL analytics across both their data warehouse tables and Amazon S3 data lakes from a single system, using consistent query syntax. Existing external tables, schemas, and even prior Spectrum queries remain unchanged, ensuring a seamless migration and no requirement to recreate assets or modify application code.
- Enhanced Security and Governance: By executing data lake queries on cluster nodes, all data processing remains within the customer’s Virtual Private Cloud (VPC) boundary. This improves data governance, enhances security posture, and simplifies compliance efforts, as sensitive data never leaves the controlled network environment. Existing IAM roles for data access continue to function as before.
This integrated approach is a clear endorsement of the "lakehouse" paradigm, where the strengths of data warehouses (performance, transactions, governance) and data lakes (scale, cost-effectiveness, flexibility) are combined into a cohesive analytics platform. It reduces total analytics costs for customers running combined data warehouse and data lake workloads, while simultaneously simplifying operations.
Instance Specifications and Migration Path
AWS has provided a clear comparison between the new RG instances and the current RA3 instances to guide customers in their migration and deployment decisions.
| Current RA3 Instance | Recommended RG instance | vCPU | Memory (GB) | Primary Use Case |
|---|---|---|---|---|
ra3.xlplus |
rg.xlarge |
4 | 32 | Small cluster departmental analytics |
ra3.4xlarge |
rg.4xlarge |
12 – 16 | 96 GB – 128 GB | Standard production workloads, medium data volumes |
The rg.xlarge instance, with 4 vCPUs and 32GB of memory, is recommended for smaller departmental analytics clusters, offering a modern and efficient option for entry-level deployments. For more demanding production workloads and medium data volumes, the rg.4xlarge instance, with 12-16 vCPUs and 96GB-128GB of memory, provides a robust upgrade path from ra3.4xlarge, promising significant performance gains and cost efficiencies. The specific vCPU and memory ratios (e.g., 1.33:1 for rg.4xlarge over ra3.4xlarge) underscore the optimized resource allocation of the Graviton architecture.

Migrating to RG instances is designed to be straightforward. Customers can launch new clusters directly using the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS API. For existing clusters, AWS provides optimal migration paths that allow customers to estimate costs, validate compatibility, and automate the execution of the migration process. The seamless nature of the transition, where external tables, schemas, and query syntax remain unchanged, minimizes disruption and accelerates adoption. The integrated data lake query engine is enabled by default, ensuring immediate access to its benefits upon deployment.
Broader Impact and Strategic Implications
The introduction of Amazon Redshift RG instances represents more than just a technical upgrade; it’s a strategic move by AWS to solidify Redshift’s position as a leading cloud data warehouse in an increasingly complex and AI-driven data landscape.
- Addressing the AI Agent Challenge: The explicit mention of "AI agents" as a primary driver for these new instances highlights AWS’s foresight. As AI models become more sophisticated and autonomous, their reliance on vast, real-time data for decision-making and learning will only intensify. Redshift RG instances, with their high query volumes, low-latency capabilities, and integrated data lake access, are perfectly positioned to serve as the analytical backbone for these next-generation AI applications, preventing the "spiraling operational costs" that could otherwise derail AI initiatives. This is a critical enabler for organizations building generative AI applications and intelligent automation systems.
- Strengthening the Lakehouse Architecture: By deeply integrating data lake querying into the core Redshift engine and eliminating Spectrum fees, AWS is making a strong statement about its commitment to the lakehouse paradigm. This move directly competes with other cloud data platforms that emphasize unified analytics across warehouses and lakes, such as Databricks’ Lakehouse Platform and Google BigQuery’s support for external data sources. The enhanced performance for Apache Iceberg and Parquet further reinforces Redshift’s appeal to organizations that have heavily invested in open data formats within their S3 data lakes.
- Competitive Edge in Cloud Data Warehousing: The cloud data warehousing market is highly competitive, with formidable players like Snowflake, Google BigQuery, and Microsoft Azure Synapse Analytics. Redshift RG instances, with their compelling price-performance ratio and Graviton-powered efficiency, provide AWS with a significant competitive advantage. The ability to offer more performance for less cost, especially for complex analytical and AI workloads, can be a deciding factor for enterprises evaluating cloud data warehouse solutions.
- Sustainability in Cloud Computing: While not explicitly detailed in the announcement, the use of AWS Graviton processors inherently contributes to greater energy efficiency. Graviton-powered instances typically consume less power than comparable x86 instances, leading to a smaller carbon footprint. In an era where corporate sustainability goals are paramount, offering high-performance, energy-efficient computing resources is an increasingly important differentiator.
- Empowering Data-Driven Innovation: Ultimately, faster, cheaper, and more integrated analytics capabilities empower businesses to derive deeper insights, make quicker decisions, and innovate more rapidly. From enhancing customer experiences through personalized recommendations to optimizing supply chains and accelerating scientific discovery, the advancements in Redshift RG instances provide a robust foundation for a wide array of data-driven initiatives.
Availability and Future Outlook
Amazon Redshift RG instances are now broadly available across numerous AWS Regions, including US East (N. Virginia, Ohio), US West (N. California, Oregon), various Asia Pacific regions (Hong Kong, Hyderabad, Jakarta, Malaysia, Melbourne, Mumbai, Osaka, Seoul, Singapore, Sydney, Taiwan, Tokyo), Canada (Central), Europe (Frankfurt, Ireland, Milan, London, Paris, Spain, Stockholm), and South America (São Paulo). For the most up-to-date regional availability and future roadmap, customers are advised to consult the AWS Capabilities by Region documentation.
For Redshift Provisioned clusters, customers have the flexibility to choose between On-Demand Instances with hourly billing and no long-term commitments, or Reserved Instances for significant cost savings over longer terms. Detailed pricing information is available on the Amazon Redshift Pricing page, and the AWS Pricing Calculator is recommended for estimating potential savings based on specific workload patterns.
AWS encourages customers to explore the capabilities of RG instances through the Redshift console and provide feedback via AWS re:Post for Amazon Redshift or their usual AWS Support contacts. This iterative feedback mechanism underscores AWS’s commitment to continuous improvement and customer-centric development. The rapid pace of innovation in Redshift, exemplified by this latest release, indicates a continued focus on addressing the evolving and increasingly complex demands of cloud data analytics, especially as AI agents become integral to enterprise operations. The future of data warehousing in the cloud, driven by performance, cost efficiency, and seamless integration, appears set to redefine what’s possible for data-driven organizations worldwide.





{kind=link}